An
advanced persistent threat (APT) is a prolonged and targeted
cyberattack in which an intruder gains access to a network and remains
undetected for an extended period of time.
APT attacks are initiated to steal data rather than cause damage to the target organization's network.
The goal of most APT attacks is to achieve and maintain ongoing
access to the targeted network rather than to get in and out as quickly
as possible. Because a great deal of effort and resources can go into
carrying out APT attacks, hackers typically select high-value targets,
such as nation-states and large corporations, with the goal of stealing information over a long period of time.
To gain access, APT groups often use advanced attack methods,
including advanced exploits of zero-day vulnerabilities, as well as
highly-targeted spear phishing and other social engineering
techniques. To maintain access to the targeted network without being
discovered, threat actors will continuously rewrite malicious code to
avoid detection and other sophisticated evasion techniques. Some APTs
are so complex that they require full-time administrators to maintain
the compromised systems and software in the targeted network.
The motives of advanced persistent threat actors are varied. For example, attackers sponsored by nation-states
may target intellectual property to gain a competitive advantage in
certain industries. Other targets may include power distribution and
telecommunications utilities and other infrastructure systems, social
media, media organizations, and electoral and other political targets.
Organized crime groups may sponsor advanced persistent threats to gain
information they can use to carry out criminal acts for financial gain.
Although APT attacks can be difficult to identify, data theft is never completely undetectable. However, the act of exfiltrating data
from an organization may be the only clue defenders have that their
networks are under attack. Cybersecurity professionals often focus on
detecting anomalies in outbound data to see if the network has been the
target of an APT attack.
How an APT attack works
Attackers executing APTs typically take the following sequential approach to gain and maintain ongoing access to a target:
Gain access. APT groups gain access to a target by targeting systems through the internet. Normally, through spear phishing
emails or via an application vulnerability with the intention of
leveraging any access by inserting malicious software into the target.
Establish a foothold. After gaining access to the target, threat actors use their access to do further reconnaissance. They use the malware
they've installed to create networks of backdoors and tunnels to move
around unnoticed. APTs may use advanced malware techniques such as code
rewriting to cover their tracks.
Gain even greater access. Once inside the
targeted network, APT actors may use methods such as password cracking
to gain administrative rights. This gives them more control of the
system and get even deeper levels of access.
Move laterally. Once threat actors have breached
their target systems, including gaining administrator rights, they can
then move around the enterprise network at will. They can also attempt
to access other servers, as well as other secure areas of the network.
Stage the attack. At this point, the hackers centralize, encrypt and compress the data so they can exfiltrate it.
Take the data. The attackers harvest the data and transfer it to their own system.
Remain until they're detected. Cybercriminals can repeat this process for long periods of time until they're detected, or they can create a backdoor so they can access the system again later.
Examples of advanced persistent threats
APTs are usually assigned names by their discoverers, though many
advanced persistent threat attacks have been discovered by more than one
researcher, so some are known by more than one name.
Advanced persistent threats have been detected since the early
2000s, and they date back as far as 2003 when China-based hackers ran
the Titan Rain campaign
against U.S. government targets in an attempt to steal sensitive state
secrets. The attackers targeted military data and launched APT attacks
on the high-end systems of government agencies, including NASA and the
FBI. Security analysts pointed to the Chinese People's Liberation Army
as the source of the attacks.
Some examples of advanced persistent threats include:
The Sykipot APT malware family exploits flaws in
Adobe Reader and Acrobat. It was detected in 2006, and further attacks
using the malware reportedly continued through 2013. Threat actors used
the Sykipot malware family as part of a long-running series of
cyberattacks, mainly targeting U.S. and U.K. organizations. The hackers
used a spear phishing attack that included links and malicious
attachments containing zero-day exploits in targeted emails.
The GhostNet cyberespionage operation was
discovered in 2009. Executed from China, the attacks were initiated via
spear phishing emails containing malicious attachments. The attacks
compromised computers in more than 100 countries. The attackers focused
on gaining access to the network devices of government ministries and
embassies. These attacks enabled the hackers to control these
compromised devices, turning them into listening and recording devices
by remotely switching on their cameras and audio recording capabilities.
The Stuxnet worm
used to attack Iran's nuclear program was detected by cybersecurity
researchers in 2010. It is still considered to be one of the most
sophisticated pieces of malware ever detected. The malware targeted
SCADA (supervisory control and data acquisition) systems and was spread
with infected USB devices. The U.S. and Israel have both been linked to
the development of Stuxnet, and while neither nation has officially
acknowledged its role in developing it, there have been unofficial
confirmations that they were responsible for Stuxnet.
APT28, the Russian advanced persistent threat
group also known as Fancy Bear, Pawn Storm, Sofacy Group and Sednit, was
identified by researchers at Trend Micro in 2014. APT28 has been linked
to attacks against military and government targets in Eastern Europe,
including Ukraine and Georgia, as well as campaigns targeting NATO
organizations and U.S. defense contractors.
APT29, the Russian advanced persistent threat group
also known as Cozy Bear, has been linked to a number of attacks,
including a 2015 spear phishing attack on the Pentagon, as well as the
2016 attacks on the Democratic National Committee.
APT34, an advanced persistent threat group linked
to Iran, was identified in 2017 by researchers at FireEye, but has been
active since at least 2014. The threat group has targeted companies in
the Middle East with attacks against financial, government, energy,
chemical and telecommunications companies.
APT37, also known as Reaper, StarCruft and Group 123, is an advanced persistent threat linked to North Korea
that is believed to have originated around 2012. APT37 has been
connected to spear phishing attacks exploiting an Adobe Flash zero-day
vulnerability.
Characteristics of advanced persistent threats
Advanced persistent threats often exhibit certain characteristics
reflecting the high degree of and coordination necessary to breach
high-value targets.
Most APTs are carried out in multiple phases, reflecting the same
basic sequence of gaining access, maintaining and expanding access, and
attempting to remain undetected in the victim network until the goals of
the attack have been accomplished.
Advanced persistent threats are also distinguished by their focus on
establishing multiple points of compromise. APTs usually attempt to
establish multiple points of entry to the targeted networks, which
enables them to retain access even if the malicious activity is
discovered and incident response is triggered, enabling cybersecurity defenders to close one compromise.
Detecting advanced persistent threats
Advanced persistent threats have certain warning signs despite
typically being hard to detect. An organization may notice certain
symptoms after it has been targeted by an APT, including:
unusual activity on user accounts;
extensive use of backdoor Trojan horse malware, a method that enables APTs to maintain access;
odd or uncharacteristic database activity, such as a sudden
increase in database operations involving massive quantities of data;
and
presence of unusual data files, which may indicate data that has been bundled into files to assist in the exfiltration process.
Detecting anomalies in outbound data is perhaps the best way for
cybersecurity professionals to determine if a network has been the
target of an APT attack.
Disaster Recovery plan: Disaster recovery plan is also called as business continuity plan or business process continuity plan.
DRP: DRP stands for Disaster Recovery Planning should include information security, asset security, and financial security plans.
As part of disaster recovery, it is important to have a location
from which the recovery of a failed site can take place. This location
is known as a backup site. In the event of a disaster, your site is
recreated at the specified backup site and made available. Once the
failed site is recovered, the backup site will be reverted to its
previous status.
There are three different types of backup sites:
1. Cold backup sites
2. Warm backup sites
3. Hot backup sites
1. Cold site: Here the bare minimums, such as space and
furniture are available. Everything else need to be procured. The delay
going to a fully operational site could be very large in this case
2. Warm site: Here, most of the hardware is in place, and
probably you need to recover the site from off-site backup, and
configure. The site could be restored in a reasonable amount of time.
3. Hot site: A facility designed to provide immediate
availability in the event of a system or network failure. All the
systems are appropriately configured and working. Only thing that is
required is the restoration of latest backup.
Note that onsite backup is not a back up site.
Backup concepts: It is recommended to store the backup tapes
in a secure, physically distant location. This would take care of
unforeseen disasters like natural disasters, fire, or theft. It is also
important that the backup tapes are regularly verified for proper
recovery in a test server, even though recovery is not really required
at that time. Otherwise, it may so happen that you find a backup tape
corrupt when it is really required. The backup policy identifies the
methods used to archive electronic and paper file systems. This policy
works in conjunction with the information retention and storage
policies.
A properly managed tape backups should include the following:
Regular backups according to a pre-determined plan
Verifying the backup tapes for integrity
Labeling tapes properly for easy and unique identification
Storing tapes securely at off-site location
Destroying data on old tapes before disposing off the same
There are primarily three types of backups:
1. Full backup: Here all the data gets backed up. It usually
involves huge amounts of data for large systems, and may take hours to
complete. A full backup is preferred instead of incremental or
differential backups where it is feasible. However, when there is large
amount of data, full backup is done once in a while and incremental or
differential backups are done in between. A backup plan is usually put
in place prior to taking backup of data.
2. Differential backup: A differential backup includes all
the data that has changed since last full backup. The "differential
backup" that was taken earlier (after the "full backup" but before the
current "differential backup") becomes redundant. This is because all
changed data since last "full backup" gets backed up again.
3. Incremental backup: It includes all the data changed since
last incremental backup. Note that for data restoration the full backup
and all incremental backup tapes since last full backup are required.
The archive bit is set after each incremental backup. Incremental backup
is useful for backing up large amounts of data, as it backs up only the
changes files since previous incremental backup.
The risk management process can make the
unmanageable manageable, and can allow the project manager to operate on
what seems to be a disadvantage and turn it into an advantage. Let’s
see how:
1. Risk identification
It is not possible to solve a risk if you do not know it. There are many ways to identify risk.
One way is through brainstorming, a methodology which allows a group to examine a problem.
Another method is that of individual interviews. It consists of
finding people with relevant experience, so that it is possible to
gather information that will help the project manager identify the risk
and find a possible solution.
Imagining the current project and thinking about the many factors
that can go wrong is another technique. What can you do if a key team
member is sick? What can you do if the material does not arrive within
the defined deadline? Etc.
An aid in this phase is also to read the reports of similar past
projects, verifying the presence of any problems encountered during the
path, and see how these have been solved.
2. Risk analysis
The next step is to determine the likelihood that each of these risks will occur. This information should also be included in the risk register.
When evaluating the risks of a project, it is possible to proactively
address the situation. For example, potential discussions can be
avoided, regulatory problems can be solved, new legislation must be
known, etc.
Analyzing the risks is certainly difficult. There is never a limit to the information that can be collected in this sense.
Moreover, risks must be analyzed based on qualitative and
quantitative analyzes. This means, that you determine the risk factor
based on how it will potentially affect the project through a variety of
metrics.
3. Risk prioritization
Not all risks have the same level of severity. It is
therefore necessary to assess each risk in order to know which
resources will be gathered to resolve it, when and if it occurs.
Some risks will be more acceptable, others may even risk to completely stop the project, making the situation quite serious.
Having a long list of risks can be daunting, but the project manager can manage them simply by classifying the risks as high, medium or low.
With this perspective, the project manager can then start planning how and when these risks will be addressed.
Some risks require immediate attention; these are the risks that can derail the project.
Other risks are important, they probably won’t threaten the success of the project, but will delay it.
Then, there are those risks that have little or no impact on the program and the overall project budget.
Some of these low priority risks could be important, but not enough
to be urgently addressed. Indeed, they could be somehow ignored and also
time could delete them and improve the situation.
4. Assign an owner to the risk
All the hard work of identifying and assessing risks is useless unless the project manager assigns someone to oversee the risk.
Who is the person responsible for that risk that, if this were to happen, would take charge of its resolution?
This decision, in general, is up to the project manager who knows the
level of experience and training of each team member and is therefore
able to assess the most suitable person to face a particular risk.
It is certainly important to identify the risks, but if these are not
managed by a person in charge, the work will have been completely
useless and the project will not be adequately protected.
5. Respond to the risk
Now comes the moment, when all that has been planned must be put into practice.
For each identified risk, based on priority, a mitigation plan or strategy is created.
The project manager should deal with the risk owner in order to decide together which strategy to implement to resolve the risk.
6. Risk monitoring
Obviously, every strategy to respond to the risk is useless if it is not monitored in its success – or failure.
The risk owner is also responsible for monitoring the progress towards resolution.
But also the project manager needs to stay updated in order to get an
accurate picture of the overall progress and to identify and monitor
potential new risks that may arise from the new situation.
It is better to ensure that dedicated communication channels for risk management are organized, so that important elements and information are not lost.
Risk mitigation
After the risk has been identified and assessed, the project team develops a risk mitigation plan, ie a plan to reduce the impact of an unexpected event.
Here are the four ways to manage or mitigate a risk:
Risk avoidance
Risk acceptance and sharing
Risk mitigation
Risk transfer
Each of these mitigation techniques can be an effective tool to reduce individual risks and the risk profile of the project.
Let’s see these four techniques in detail.
1. Risk avoidance
This technique usually involves developing an alternative strategy that is more likely to succeed, but is usually linked to a higher cost.
A very common risk elimination technique is to use proven and
existing technologies rather than adopting new technologies, although
they could lead to better performance or lower costs.
A project team can choose a supplier with a proven track record
instead of a new supplier that offers significant price incentives;
this, in order to avoid the risk of working with a new supplier that is
not known whether it is reliable or not.
Eliminating a risk is definitely the best technique you can use. If the project manager can avoid it, surely he will not have negative impacts derived from it on the project.
2. Risk acceptance and sharing
This technique involves accepting the risk and collaborating with others in order to share responsibility for risky activities.
Many organizations working on international projects will reduce the
political, legal, and employment risks associated with international
projects by developing a joint venture with a company based in a
particular country, for example.
Partnering with another company to share the risk associated with a
part of the project is advantageous when the other company has
experience that the project team does not have. If a risk event occurs, the partner company absorbs all or part of the negative impact of the event.
3. Risk mitigation
Risk mitigation represents an investment in order to reduce the risk on a project.
On international projects, for example, companies will often buy a
guaranteed exchange rate in order to reduce the risk associated with
exchange rate fluctuations.
A project manager can hire an expert to review technical plans or
cost estimates on a project in order to increase confidence in that
plan.
Assigning high-risk management activities to highly qualified project personnel is another risk reduction method.
Experts who run a high-risk business can often anticipate problems and find solution.
4. Risk transfer
Risk transfer is a risk reduction method that shifts risk from the project to another party.
A classic example of risk transfer is the purchase of an insurance.
The risk is transferred from the project to the insurance company.
Purchasing an insurance is usually in areas beyond the control of the
project team. Weather, political unrest, and strikes are examples of
events that can have a significant impact on the project and that are
beyond the control of the project team.
Simply put, it is simply a matter of paying someone else to accept the risk.
Risk management may seem superfluous at the beginning of the project.
When a project manager is starting a new project, it is indeed
difficult to think about things that could go wrong, especially if he is
caught up in the initial enthusiasm.
It is essential to remember, however, that the development of a
management plan will – most likely – be useful later during the
development of the project.
This is why risk management must be considered an absolute priority from the start.
There are multiple instances where an organization works with another
organization as a third party and it can bring up a variety of security
issues. A third party is an entity that isn’t directly involved in
activities between two primary parties.
In many situations, it’s
appropriate to use a non-disclosure agreement (NDA) to ensure that third
parties understand their responsibilities. This can be a completely
separate agreement, but is more commonly embedded as a clause in a
contract with the third party.
In addition to NDAs, organizations often utilize different
interoperability agreements to identify various responsibilities. These
include ISAs, SLAs, MOUs, and BPAs.
Interconnection security agreement (ISA)
An
ISA specifies technical and security requirements for planning,
establishing, maintaining, and disconnecting a secure connection between
two or more entities. For example, it may stipulate certain types of
encryption for all data in transit.
Service level agreement (SLA)
An
SLA is an agreement between a company and a vendor that stipulates
performance expectations, such as minimum uptime and maximum downtime
levels. Organizations use SLAs when contracting services from service
providers such as Internet Service Providers (ISPs). Many SLAs include a
monetary penalty if the vendor is unable to meet the agreed-upon
expectations.
Memorandum of understanding (MOU)
An
MOU expresses an understanding between two or more parties indicating
their intention to work together toward a common goal. It is similar to
an SLA in that it defines the responsibilities of each of the parties.
However, it is less formal than an SLA and does not include monetary
penalties. Additionally, it doesn’t have strict guidelines in place to
protect sensitive data.
Many times, MOUs are used in conjunction with ISAs. National Institute of Standards and Technology (NIST) Special Publication (SP) 800-47, “Security Guide for Interconnecting Information Technology Systems,” includes more in-depth information on MOUs and ISAs.
Business partners agreement (BPA)
A
BPA is a written agreement that details the relationship between
business partners, including their obligations toward the partnership.
It typically identifies the shares of profits or losses each partner
will take, their responsibilities to each other, and what to do if a
partner chooses to leave the partnership. One of the primary benefits of
a BPA is that it can help settle conflicts when they arise.
Q. Your organization is considering storage of sensitive data in a
cloud provider. Your organization wants to ensure the data is encrypted
while at rest and while in transit. What type of interoperability
agreement can your organization use to ensure the data is encrypted
while in transit?
A. SLA
B. BPA
C. MOU
D. ISA
Answer. D is correct.
An interconnection security agreement (ISA) specifies technical and
security requirements for secure connections and can ensure data is
encrypted while in transit.
None of the other agreements address the connection.
Having a well-developed security posture is essential to any
business. Organizations should not assume the security of their
customers' data and instead must take proactive steps to ensure it
throughout the development process. Veracode provides powerful
cloud-based tools, including static and dynamic security analysis, to detect vulnerabilities and security flaws before attackers can take advantage of them.
One common threat to be wary of is spoofing, where an attacker fakes
an IP address or other identifier to gain access to sensitive data and
otherwise secure systems. According to a 2018 report by the Center for Applied Internet Data Analysis (CAIDA), there are close to 30,000 spoofing attacks per day.
What Is a Spoofing Attack?
Spoofing is when an attacker impersonates an authorized device or user to steal data, spread malware, or bypass access control systems.
There are many different types of spoofing, with three of the most common being:
IP address spoofing - Attacker sends packets over the network from a false IP address
ARP spoofing - Attacker links their MAC address to an authorized IP address already on the network
DNS spoofing - Attacker initiates a threat such as cache poisoning
to reroute traffic intended for a specific domain name traffic to a
different IP address
IP Address Spoofing Attacks
An IP (Internet Protocol) address is a unique number used to identify
a specific computer on a network. In IP address spoofing, attackers
manipulate the IP header so that the packet appears to be coming from a
legitimate source. This tricks the target machine into accepting
malicious code or giving attackers access to sensitive data.
IP address spoofing can be used to carry out a denial-of-service
attack. In this attack, attackers flood the network with more data than
it can handle by sending hundreds or thousands of IP packets from
multiple spoofed IP addresses. Alternatively, a specific machine's
address can be spoofed to send many packets to other machines on the
same network. Because machines automatically send responses when they
receive an IP packet, this results in the spoofed machine being knocked
offline.
Another way attackers use IP spoofing is to bypass authentication
that relies upon a device’s IP address. Systems designed to assume a
specific list of IP addresses is trustworthy can be tricked into
accepting connections from untrusted machines that spoof a trusted
machine’s IP address.
ARP Spoofing Attacks/ARP Cache Poisoning
ARP (Address Resolution Protocol) is used to identify legitimate
machines on a network by resolving IP addresses to a specific MAC (Media
Access Control) address. In ARP spoofing,
an attacker sends ARP packets to the network, which appear to be from
these legitimate devices. Because other machines on the network will
think the attacker is legitimate, they will gladly send data back, which
the attacker can use for other, more sophisticated attacks.
Successful ARP spoofing can be used to carry out:
Denial-of-service attacks, where networks or machines are flooded with bogus data and taken offline
Session hijacking, in which attackers exploit in-progress
authentication by legitimate users to gain unauthorized access to data
and devices
Man-in-the-middle attacks, where attackers impersonate multiple devices to steal data intended for legitimate devices
DNS Spoofing Attacks
In DNS spoofing, an attacker provides false information to the DNS
(Domain Name System) facility used by a given system, usually by
inserting incorrect information into the local DNS cache. When an
application needs to access a network resource by hostname, the system
looks up the correct IP address associated with that name by using a DNS
query to a DNS server that’s configured for the network. To reduce load
on that server, most systems cache the responses to DNS queries for a
time – so if an attacker is able to alter the contents of that cache,
they can trick applications into accessing an IP different from those
registered in the DNS system for a given hostname.
DNS server spoofing is often used to route web traffic to a server
under the attacker's control and deliver computer viruses, and other
malware onto users' machines, or to trick the user into supplying
sensitive information.
How to Prevent and Mitigate Spoofing Attacks
Spoofing attacks can have disastrous consequences, but there are ways to reduce their likelihood and prevent them altogether.
Employ Packet Filtering with Deep Packet Inspection
Packet filtering analyzes IP packets and blocks those with
conflicting source information. Because malicious packets will come from
outside the network despite what their headers say, this is a good way
to eliminate spoofed IP packets. Because attackers have developed
techniques for evading simple packet filters, most packet-filter systems
offer a DPI (Deep Packet Inspection) feature. DPI allows you to define
rules based on both the header and the content of network packets,
allowing you to filter out many kinds of IP spoofing attacks.
Authenticate users and systems
If devices on a network use only IP addresses for authentication, IP
spoofing can bypass the authentication control. Connections between
devices should be authenticated by the individual users or applications,
or by using authenticity systems such as mutual certificate auth,
IPSec, and domain authentication.
Use Spoofing Detection Software
Several programs help detect spoofing attacks, especially ARP
spoofing. Consider a tool like NetCut, Arp Monitor, or arpwatch for ARP
spoofing defense. These and other tools can inspect and certify
legitimate data before it is received by a target machine can
significantly lower the success of spoofing attacks.
Use Encrypted and Authenticated Protocols
Security experts have developed several secure communications protocols, including Transport Layer Security (TLS) (used by HTTPS and FTPS),
Internet Protocol Security (IPSec), and Secure Shell (SSH). When used
properly, these protocols authenticate the application or device to
which you’re connecting, and encrypt data in transit, reducing the
likelihood of a successful spoofing attack.
Security orchestration, automation, and response (SOAR) solutions help teams to enhance their security posture
and develop efficiency without overlooking critical security and IT
processes. This is achieved with the help of playbooks, which are a
built-in capability of SOAR solutions that carry out various tasks and
workflows based on rules, triggers, and events. Integrating SOAR into an
organization’s security operations center (SOC) can boost the overall
security efficiency and effectiveness by automating tasks, coordinating
alerts from multiple security devices, and providing playbooks for incident response.
SOAR solutions utilize varied playbooks to automate responses to
different kinds of threats without any manual intervention. These
playbooks ensure that the security processes are uniformly executed
throughout a company’s SOC.
SOAR Workflow Versus Playbook
While SOAR workflow is a collection of tasks in a playbook, sets of workflows are known as playbooks that allow SOAR platforms
to automatically take action when an incident occurs. Using SOAR
playbooks, security teams can handle alerts, create automated responses
for different incident types, and quickly resolve issues, more
effectively and consistently. With SOAR playbooks, security teams can
build workflows that require minimal to no human intervention. These
playbooks also facilitate the automated incident investigation, threat intelligence enrichment, incident actioning such as blocking of malicious indicators of compromise (IOCs), and automated threat data dissemination to security tools such as SIEMs, firewalls, threat intelligence platforms (TIPs), incident response platforms, and others.
Why are SOAR Playbooks Needed?
SOAR
playbooks enable security teams to expedite and streamline
time-consuming processes. Equipped with capabilities to integrate
security tools and establish seamless customizable workflows, these
playbooks allow security teams to automate mundane and repetitive tasks
while freeing human analysts for more important tasks dependent on human
intelligence and decision making. Nowadays, modern security playbooks
come with “holdable” features allowing them to integrate human decision
making with automation for highly critical security situations. With
considerable productivity gains and time savings across overall security
operations, security teams can move from overwhelmed to functioning at
maximum efficiency in no time.
SOAR Playbook Use Cases
Threat Intelligence Automation
Threat intelligence enrichment
is an important aspect of any incident or threat investigation process.
This enrichment process eliminates false positives and collects actionable intelligence for threat response and other security operations. SOAR playbooks automatically ingest and normalize indicators of compromise (IOCs)
from external and internal intelligence sources and enrich the
collected IOCs. Following the enrichment process, the playbooks can
automatically score the intel and prioritize the further response
steps.
Automated Incident Response
With
advanced threat contextualization, analysis, and SOAR playbooks,
security teams can have intel-driven responses to all security threats
and incidents. SOAR playbooks allow security teams to leverage the power
of automation to detect, analyze, enrich, and respond to threats at
machine speed. SOAR playbooks can also be used to block threat
indicators (IOCs) on Firewall, EDR, SIEM, and other tools.
Vulnerability Management
SOAR
playbooks enable security teams to instantaneously respond to
vulnerabilities by automatically applying or scheduling patches. SOAR
playbooks can also be used to ensure that security teams stay informed
about all the current vulnerabilities and that they successfully
evaluate the potential risk of every vulnerability in order to take
appropriate risk mitigation measures. Besides providing information to
the teams, SOAR playbooks can be employed to query a database of
vulnerabilities, active directories for asset information, or EDR tools
for events to collect additional information on vulnerabilities.
Improved Threat Hunting
With new vulnerabilities and attacks emerging constantly, threat hunting is becoming not only a challenge but a priority. Using SOAR playbooks, security teams can automate threat hunting
processes to identify suspicious domains, malware, and other
indicators, accelerating the hunting process and freeing themselves to
tackle critical challenges. With the help of SOAR playbooks, security
teams can move beyond alert fatigue, responding to incidents before the
moment of impact.
Automated Patching and Remediation
From notifications to remediation of threats, vulnerability management
processes can be orchestrated by integrating SOAR playbooks into a
company’s existing solutions. The playbooks automate actions to scan,
discover patches, validate remediation, and more, addressing critical
issues.
Phishing Email Investigations
Phishing has been one of the major attack vectors for data breaches. With the phishing incident response playbook,
security teams don’t need to manually investigate every URL,
attachment, or dubious request for sensitive information. A phishing incident response playbook allows security teams to focus on alleviating malicious content and training employees on phishing best practices.
To
quickly respond to phishing attacks, security teams can employ
automated phishing incident response playbooks. The automated phishing
incident response playbooks standardize the response process from
detection to blocking of the malicious indicators from where attacks are
sourced.
Malware Containment
With
the increasing risk of ransomware, spyware, viruses, and more, security
teams are grappling with a plethora of malicious programs. SOAR
playbooks can automatically investigate and contain malware before they spread and damage an organization’s network.
Employee Provisioning and Deprovisioning
Every
company should be able to quickly and effectively manage user
permissions in order to respond to a wide range of security threats.
However, it is a critical task and most organizations can’t keep up.
From provisioning and deprovisioning users to responding to incidents,
SOAR playbooks can put an end to the burden of manually handling user
accounts in diverse use cases.
Ease of Communication
When
alerts are received, SOAR playbooks trigger workflows, issuing help
desk tickets, initiating investigation and enrichment tasks, and so on.
The playbooks can be integrated with other workflow management solutions
to establish seamless communication between security, development, and
IT teams. Security teams can access central communication hubs to
improve visibility and efficiently coordinate processes.
Benefits of SOAR Playbooks
Standardized Processes
SOAR
solutions fill in for security analysts and relieve them of monotonous
tasks, and include these tasks in an overall process of handling any
incident. A good SOAR solution incorporates these tasks into playbooks that outlay the step-by-step incident response.
Streamlined Operations
Every aspect of SOAR playbooks contributes to simplify security operations. While security orchestration
aggregates data influx from multiple sources, security automation
controls low-priority alerts and incidents with the help of automated
playbooks.
Technology and Tools Integration
A
SOAR playbook can be integrated into products across various security
technologies such as cloud security, forensics, and malware analysis,
vulnerability and risk management, data enrichment, threat intelligence, incident response, and endpoint security among others. The integration of these technologies into a SOAR solution can be seamless.
Risk management is the practice of identifying, monitoring, and
limiting risks to a manageable level. It doesn’t eliminate risks, but
instead identifies methods to limit or mitigate them. The amount of risk
that remains after managing risk is residual risk.
Senior
management is ultimately responsible for residual risk—the amount of
risk that remains after mitigating risk. Management must choose a level
of acceptable risk based on the organization’s goals. They use a
variety of tools and metrics to identify the risks, and then decide what
resources (such as money, hardware, and time) to dedicate to manage the
risk.
Some of the common metrics they use are:
Mean time between failures (MTBF)
Mean time to failure (MTTF)
Mean time to recover (MTTR)
What is Failure?
These
metrics are important to understand when evaluating the failure rate of
critical business systems. Typically, a critical business system will
have multiple redundancies in place to ensure it stays operational even
after a fault occurs. In other words, critical systems can tolerate
faults without actually failing.
If a server has one hard drive, and the one hard drive fails, the server fails. This is a system failure.
However,
if a server has a redundant array of independent disks 6 (RAID- 6), and
one drive fails, the server continues to operate. This is not a system
failure.
Mean Time Between Failures (MTBF)
The mean time
between failures (MTBF) metric provides a measure of a system’s
reliability and is usually represented in hours. More specifically,
the MTBF identifies the average (the arithmetic mean) time between
failures.
Higher MTBF numbers indicate a higher reliability of a
product or system. Administrators and security experts attempt to
identify the MTBF for critical systems with a goal of predicting
potential outages.
Mean Time to Failure (MTTF)
The mean
time to failure (MTTF) is the length of time you can expect a device to
remain in operation before it fails. It is similar to MTBF, but the
primary difference is that “between” in the MTBF metric indicates you can repair the device after it fails.
In
contrast, the MTTF metric indicates that you will not be able to repair
a device after it fails. It is permanent. For example, the MTTF of a
power supply within a server indicates how long the power supply may
last before it fails and needs to be replaced.
Mean Time to Recover (MTTR)
The
mean time to recover (MTTR) identifies the average (the arithmetic
mean) time it takes to restore a failed system. In some cases, people
interpret MTTR as the mean time to repair, and both mean essentially the
same thing.
Organizations that have maintenance contracts, such
as service level agreements (SLEs), often specify the MTTR as a part of
the contract. The supplier agrees that it will, on average, restore a
failed system within the MTTR time.
The MTTR
does not provide a guarantee that the supplier will restore the system
within the MTTR every time. Sometimes it may take a little longer and
sometimes it may be a little quicker, with the average defined by the
MTTR.
MTBF, MTTF, MTTR Summary
As a short summary these metrics are:
Mean
time between failure (MTBF) – provides a measure of a system’s
reliability and identifies the average time between failures. It is
often used to predict potential outages with critical systems.
Mean
time to failure (MTTF) – the length of time you can expect a device to
remain in operation before it fails. It indicates failure is permanent,
while MTBF indicates it can be repaired.
Mean time to repair (MTTR) – the average time it takes to restore a failed system.
The acronym RAID stands for Redundant Array of Inexpensive Disks and is a technology that provides increased storage functions and reliability through redundancy.
It was developed using a large number of low cost hard drives linked
together to form a single large capacity storage device that offered
superior performance, storage capacity and reliability over older
storage systems. This was achieved by combining multiple disk drive
components into a logical unit, where data was distributed across the
drives in one of several ways called "RAID levels".
This concept of storage virtualization and was first defined as
Redundant Arrays of Inexpensive Disks but the term later evolved into Redundant Array of Independent Disks as a means of dissociating a low-cost expectation from RAID technology.
There are two primary reasons that RAID was implemented:
Redundancy: This is the most important factor in the
development of RAID for server environments. A typical RAID system will
assure some level of fault tolerance by providing real time data recovery with uninterrupted access when hard drive fails;
Increased Performance: The increased performance is only
found when specific versions of the RAID are used. Performance will also
be dependent upon the number of drives used in the array and the
controller;
Hardware-based RAID
When using hardware RAID controllers, all algorithms are generated
on the RAID controller board, thus freeing the server CPU. On a desktop
system, a hardware RAID controller may be a PCI or PCIe expansion card
or a component integrated into the motherboard. These are more robust
and fault tolerant than software RAID but require a dedicated RAID
controller to work.
Hardware implementations provide guaranteed performance, add no
computational overhead to the host computer, and can support many
operating systems; the controller simply presents the RAID array as
another logical drive
Software-based RAID
Many operating systems provide functionality for implementing
software based RAID systems where the OS generate the RAID algorithms
using the server CPU. In fact the burden of RAID processing is borne by a
host computer's central processing unit rather than the RAID controller
itself which can severely limit the RAID performance.
Although cheap to implement it does not guarantee any kind of fault
tolerance; should a server fail the whole RAID system is lost.
Hot spare drive
Both hardware and software RAIDs with redundancy may support the use of hot spare drives, a drive
physically installed in the array which is inactive until an active
drive fails. The system then automatically replaces the failed drive
with the spare, rebuilding the array with the spare drive included. This
reduces the mean time to recovery (MTTR),
but does not completely eliminate it. Subsequent additional failure(s)
in the same RAID redundancy group before the array is fully rebuilt can
result in data loss. Rebuilding can take several hours, especially on
busy systems.
Standard RAID Levels
RAID 0
Striped Disk Array without Fault Tolerance:
Provides data striping spreading out blocks of each file across multiple
disk drives, the data is broken down into blocks and each block is
written to a separate disk drive therefore I/O performance is greatly
improved by spreading the I/O load across many channels and drives. This
is not a true RAID because it doesn't provide any redundancy and it is
not fault-tolerant; the failure of just one drive will result in all
data in an array being lost.
RAID 0 can only be used for tasks requiring fast access to a large
capacity of temporary disk storage (such as video/audio post-production,
multimedia imaging, CAD, data logging, etc.) where in case of a disk
failure, the data can be easily reloaded without impacting the business.
RAID 0 offers low cost and maximum performance and there are also no cost disadvantages as all available drives are used.
RAID 1
Mirroring and Duplexing: Provides disk mirroring
allowing for twice the read transaction rate of single disks and the
same write transaction rate as single disks. The transfer rate per block
is equal to that of a single disk providing 100% redundancy of data
which means no rebuild is necessary in case of a disk failure, just copy
to the replacement disk.
RAID 1 provides cost-effective and high fault tolerance however it has
the highest disk overhead of all RAID types because the usable capacity
is 50% of the available drives in the RAID set.
RAID 2
Error Correcting Coding: Not a typical implementation
and rarely used, RAID 2 stripes data at the bit level rather than the
block level writing each bit of data word to a data disk drive (4 in
this example: 0 to 3).
Each data word has its Hamming Code ECC word recorded on the ECC disks.
Upon read, the ECC code verifies correct data or corrects single disk
errors. It has "On the fly" data error correction allowing for
extremely high data transfer rates. However it is not used anymore
because all modern disks have built in error correction.
RAID 3
Bit-Interleaved Parity (or Parallel Transfer With Parity)
: The data block is subdivided ("striped"), providing byte-level
striping, and written on the data disks while stripe parity is written
on a dedicated parity disk.
This level, which cannot service simultaneous multiple requests, also is rarely used.
RAID 4
Dedicated Parity Drive: Level 4 provides block-level
striping (like Level 0) with a parity disk. Each entire block is written
onto a data disk. Parity for same rank blocks is generated on Writes,
recorded on the parity disk and checked on Reads If a data disk fails,
the parity data is used to create a replacement disk.
A disadvantage to Level 4 is that the parity disk can create write bottlenecks because parity has to be systematically updated.
RAID 5
Block Interleaved Distributed Parity: Provides data
striping at the byte level and also stripe error correction information.
Data is striped across all of the drives in the array, but for each
stripe through the array (one stripe unit from each disk) one stripe
unit is reserved to hold parity data calculated from the other stripe
units in the same stripe. This results in excellent performance and good
fault tolerance. Level 5 is one of the most popular implementations of
RAID.
The RAID 5 parity requires one disk drive per RAID set, so usable
capacity will always be one disk drive less than the number of available
disks.
RAID 6
Independent Data Disks with Double Parity: Provides
block-level striping with parity data distributed across all disks. To
prevent data loss, a second set of parity information is added; using
the stripes of parity information already created, the controller can
generate another parity set.
RAID 6 provides an extremely high data fault tolerance and can sustain multiple simultaneous drive failures.
Non Standard RAID Levels
There are several non-standard RAID levels but some of them are
proprietary systems develop and sold only by a single company. Here are
the most common ones:
RAID 0+1
Mirror of Stripes: RAID 0+1 is implemented as a
mirrored array whose segments are RAID 0 arrays. Used for both
replicating and sharing data among disks.
Can sustain a single drive failure causing the whole array to become, in
essence, a single RAID 0 array. It is very expensive with a high
overhead.
RAID 10
Stripe of Mirrors: RAID 10 is implemented as a striped
array whose segments are RAID 1 mirrors. This level provides the
improved performance of striping while still providing the redundancy of
mirroring. RAID 10 has the same fault tolerance as RAID level 1; up to
one disk of each sub-array may fail without causing loss of data.
This level has the same overhead as mirroring alone so the usable
capacity of RAID 10 is 50% of available disk drives making it very
expensive.
RAID 50
RAID 50 comprises RAID 0 striping across lower-level RAID 5 arrays. High
data transfer rates are achieved thanks to its RAID 5 array segments
while the spanned RAID 0 allows the incorporation of many more disks
into a single logical drive. RAID 50 is more fault tolerant than RAID 5
but has twice the parity overhead thus making it very expensive to
implement.
Most current RAID 50 implementation is illustrated above. Failure of two
drives in one of the RAID 5 segments renders the whole array unusable
but the whole set can sustain the failure of one disk in each sub set
without data loss.
Quick Assist
is widely used to offer remote assistance to a remote computer. If you
have ever encountered Quick Assist black screen admin when trying to run
a program as an administrator, keep reading to realize two methods to
go into Quick Assist administrator mode.
Method 1. Disable PromptOnSecureDesktop using Registry
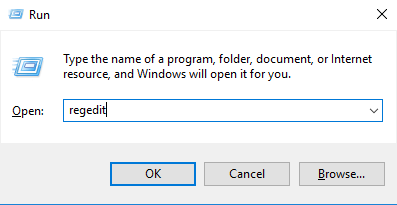
Step 1. Press Win + R to invoke the Run dialog box, then type in “regedit” and press OK to open Registry.
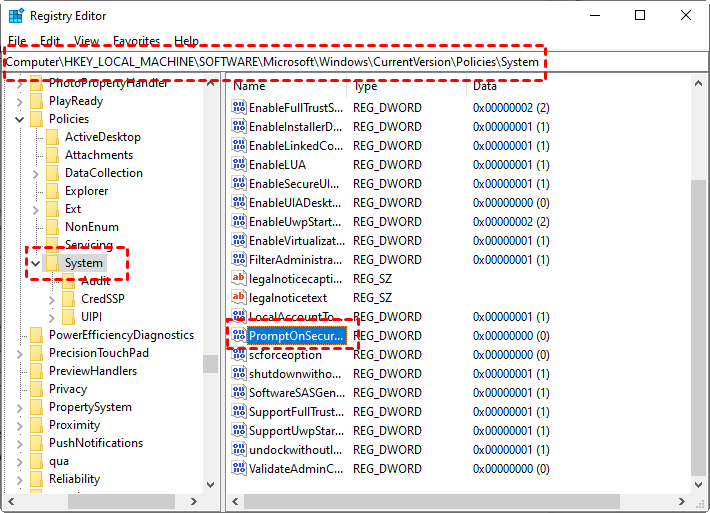
Step 2. Navigate to: Computer > HKEY_LOCAL_MACHINE > SOFTWARE > Microsoft > Windows > CurrentVersion > Policies > System. On the right pane, find and double-click PromptOnSecureDesktop.
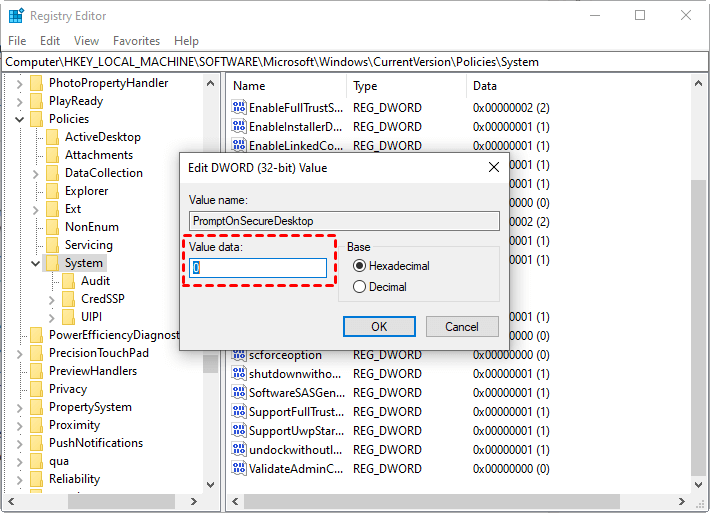
Step 3. Change its value data to 0 to disable it.
Method 2. Disable User Account Control in Group Policy
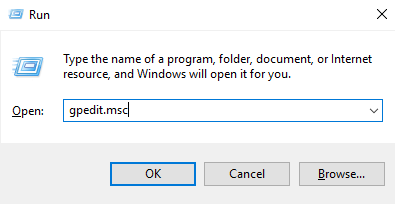
Step 1. Press Win + R to open the run dialog box, and type in “gpedit.msc” to open the Local Group Policy Editor.
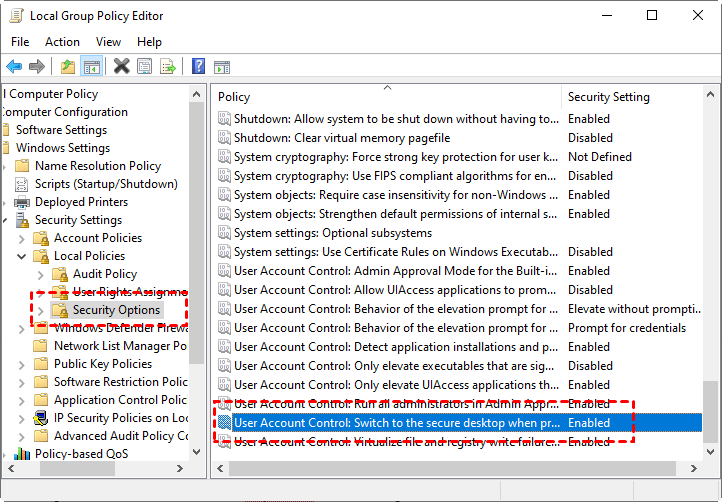
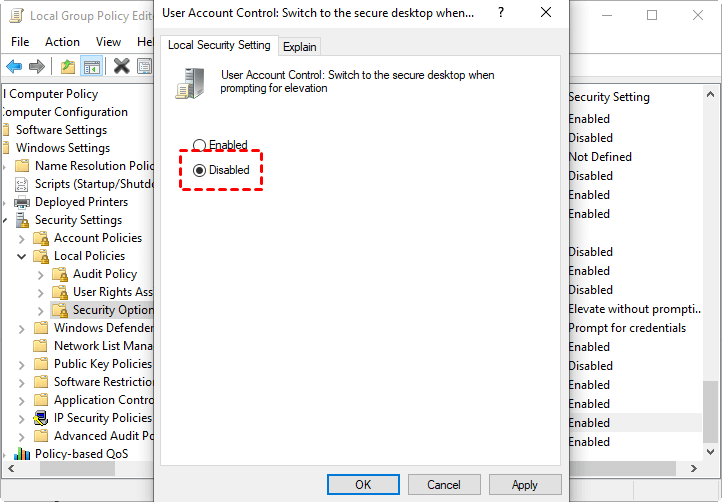
Step 2. Navigate to: Computer Configuration > Windows Settings > Security Settings > Local Policies > Security Options. Find and double-click User Account Control: Switch to the secure desktop when prompting for elevation.
Step 3. Change its status to Disabled.
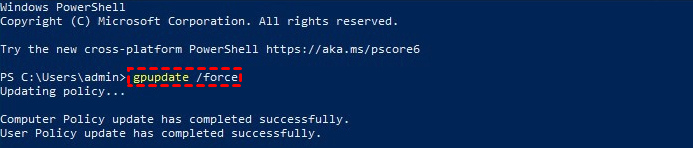
Step 4. Open Windows PowerShell and run gpupdate /force to update your computer to the latest group policy settings.
Suppose you are using Quick Assist to provide others with remote
support and can’t run programs as an administrator on their computers.
In that case, we provide you with two methods to help you go into
Microsoft Quick Assist administrator mode. But pay attention; disabling
these two policies would also be a big security risk. So please do it
after careful consideration.
A
proxy server acts as a gateway between you and the internet. It’s an
intermediary server separating end users from the websites they browse.
Proxy servers provide varying levels of functionality, security, and
privacy depending on your use case, needs, or company policy.
If
you’re using a proxy server, internet traffic flows through the proxy
server on its way to the address you requested. The request then comes
back through that same proxy server (there are exceptions to this rule),
and then the proxy server forwards the data received from the website
to you.
If that’s all it does, why bother with a proxy server? Why not just go straight from to the website and back?
Modern
proxy servers do much more than forwarding web requests, all in the
name of data security and network performance. Proxy servers act as a
firewall and web filter, provide shared network connections, and cache
data to speed up common requests. A good proxy server keeps users and
the internal network protected from the bad stuff that lives out in the
wild internet. Lastly, proxy servers can provide a high level of
privacy.
How Does a Proxy Server Operate?
Every
computer on the internet needs to have a unique Internet Protocol (IP)
Address. Think of this IP address as your computer’s street address.
Just as the post office knows to deliver your mail to your street
address, the internet knows how to send the correct data to the correct
computer by the IP address.
A proxy server is basically a computer
on the internet with its own IP address that your computer knows. When
you send a web request, your request goes to the proxy server first. The
proxy server then makes your web request on your behalf, collects the
response from the web server, and forwards you the web page data so you
can see the page in your browser.
When the proxy server forwards
your web requests, it can make changes to the data you send and still
get you the information that you expect to see. A proxy server can
change your IP address, so the web server doesn’t know exactly where you
are in the world. It can encrypt your data, so your data is unreadable
in transit. And lastly, a proxy server can block access to certain web
pages, based on IP address.
Why Should You Use a Proxy Server?
There are several reasons organizations and individuals use a proxy server.
To control internet usage of employees and children: Organizations
and parents set up proxy servers to control and monitor how their
employees or kids use the internet. Most organizations don’t want you
looking at specific websites on company time, and they can configure the
proxy server to deny access to specific sites, instead of redirecting
you with a nice note asking you to refrain from looking at said sites on
the company network. They can also monitor and log all web requests, so
even though they might not block the site, they know how much time you
spend cyberloafing.
Bandwidth savings and improved speeds: Organizations
can also get better overall network performance with a good proxy
server. Proxy servers can cache (save a copy of the website locally)
popular websites – so when you ask for www.varonis.com, the proxy server
will check to see if it has the most recent copy of the site, and then
send you the saved copy. What this means is that when hundreds of people
hit www.varonis.com at the same time from the same proxy server, the
proxy server only sends one request to varonis.com. This saves bandwidth
for the company and improves the network performance.
Privacy benefits: Individuals and organizations
alike use proxy servers to browse the internet more privately. Some
proxy servers will change the IP address and other identifying
information the web request contains. This means the destination server
doesn’t know who actually made the original request, which helps keeps
your personal information and browsing habits more private.
Improved security: Proxy servers provide security
benefits on top of the privacy benefits. You can configure your proxy
server to encrypt your web requests to keep prying eyes from reading
your transactions. You can also prevent known malware sites from any
access through the proxy server. Additionally, organizations can couple
their proxy server with a Virtual Private Network (VPN), so remote users
always access the internet through the company proxy. A VPN is a direct
connection to the company network that companies provide to external or
remote users. By using a VPN, the company can control and verify that
their users have access to the resources (email, internal data) they
need, while also providing a secure connection for the user to protect
the company data.
Get access to blocked resources: Proxy servers
allow users to circumvent content restrictions imposed by companies or
governments. Is the local sportsball team’s game blacked out online? Log
into a proxy server on the other side of the country and watch from
there. The proxy server makes it look like you are in California, but
you actually live in North Carolina. Several governments around the
world closely monitor and restrict access to the internet, and proxy
servers offer their citizens access to an uncensored internet.
Now that you have an idea about why organizations and individuals use a proxy server, take a look at the risks below.
Proxy Server Risks
You do need to be cautious when you choose a proxy server: a few common risks can negate any of the potential benefits:
Free proxy server risks
You know the old saying “you get what you pay for?” Well, using one of the many free proxy server services can be quite risky, even the services using ad-based revenue models.
Free usually means they aren’t investing heavily in backend hardware
or encryption. You’ll likely see performance issues and potential data
security issues. If you ever find a completely “free” proxy server,
tread very carefully. Some of those are just looking to steal your
credit card numbers.
Browsing history log
The proxy server has your original IP address and web request
information possibly unencrypted saved locally. Make sure to check if
your proxy server logs and saves that data – and what kind of retention
or law enforcement cooperation policies they follow.
If you expect to use a proxy server for privacy, but the vendor is
just logging and selling your data you might not be receiving the
expected value for the service.
No encryption
If you use a proxy server without encryption, you might as well not
use a proxy server. No encryption means you are sending your requests as
plain text. Anyone who is listening will be able to pull usernames and
passwords and account information really easily. Make sure whatever
proxy server you use provides full encryption capability.
Types of Proxy Servers
Not
all proxy servers work the same way. It’s important to understand
exactly what functionality you’re getting from the proxy server and
ensure that the proxy server meets your use case.
Transparent Proxy
A transparent proxy tells websites that it is a proxy server and it
will still pass along your IP address, identifying you to the webserver.
Businesses, public libraries, and schools often use transparent proxies
for content filtering: they’re easy to set up both client and
server-side.
Anonymous Proxy
An anonymous proxy will identify itself as a proxy, but it won’t
pass your IP address to the website – this helps prevent identity theft
and keep your browsing habits private. They can also prevent a website
from serving you targeted marketing content based on your location. For
example, if CNN.com knows you live in Raleigh, NC, they will show you
news stories they feel are relevant to Raleigh, NC. Browsing anonymously
will prevent a website from using some ad targeting techniques, but is
not a 100% guarantee.
Distorting proxy
A distorting proxy server passes along a false IP address
for you while identifying itself as a proxy. This serves similar
purposes as the anonymous proxy, but by passing a false IP address, you
can appear to be from a different location to get around content restrictions.
High Anonymity proxy
High Anonymity proxy servers periodically change the IP address they
present to the web server, making it very difficult to keep track of
what traffic belongs to who. High anonymity proxies, like the TOR Network, is the most private and secure way to read the internet.
Proxy servers are a hot item in the news these days with the controversies around Net Neutrality and censorship.
By removing net neutrality protections in the United States, Internet
Service Providers (ISP) are now able to control your bandwidth and
internet traffic. ISPs can potentially tell you what sites you can and
cannot see. While there’s a great amount of uncertainty around what is
going to happen with Net Neutrality, it’s possible that proxy servers
will provide some ability to work around an ISPs restrictions.
These settings can be accessed through Chrome’s “Advanced Settings” menu or by navigating to “chrome://settings/."
Enable phishing and malware protection: Make
sure that Chrome’s phishing and malware protection feature is enabled
under the “Privacy” section. This feature will warn you if a site you’re
trying to visit may be phishing or contain malware.
Turn off instant search: The Instant search feature
should be turned off for optimal security. While it offers some
convenience in searching, having this feature enabled means that
anything you type in the address bar is instantly sent to Google.
Don’t sync: Disconnect your email account from your
browser under the “Personal Stuff” tab. Syncing your email account with
your Chrome browser means that personal information such as passwords,
autofill data, preferences, and more is stored on Google’s servers. If
you must use sync, select the “Encrypt all synced data” option and
create a unique passphrase for encryption.
Configure content settings: Click “Content settings” under the “Privacy” section and do the following:
Cookies: Select “Keep local data only until I quit my
browser” and “Block third-party cookies and site data.” These options
ensure that your cookies will be deleted upon quitting Chrome and that
advertisers will not be able to track you using third-party cookies.
JavaScript: Select “Do not allow any site to run
JavaScript.” It is widely recommended that JavaScript be disabled
whenever possible to protect users from its security vulnerabilities.
Pop-ups: Select “Do not allow any site to show pop-ups.
Location: Select “Do not allow any site to track my physical location.”
Configure passwords and forms settings: Disable
Autofill and deselect “Offer to save passwords I enter on the web” under
the “Passwords and forms” section. Doing so will prevent Chrome from
saving your logins, passwords, and other sensitive information that you
enter into forms.
Tips for Secure Browsing with Mozilla Firefox
These settings can be accessed through the “Options” menu.
Configure privacy settings: Under the “Privacy”
tab, complete the following steps. These measures ensure that Firefox
is storing only as much of your information as it needs to function
normally.
Select “Use custom settings for history.”
Deselect “Remember my browsing and download history.”
Deselect “Remember search and form history.”
Deselect “Accept third-party cookies.”
Set cookie storage to “Keep until I close Firefox.”
Select “Clear history when Firefox closes.”
Configure security settings: Under the “Security”
tab, choose the following settings. These steps prevent Firefox from
saving your passwords and keep you from visiting potentially harmful
sites.
Verify that “Warn me when sites try to install add-ons,” “Block
reported attack sites,” and “Block reported web forgeries” are all
selected.
Deselect “Remember passwords for sites.”
Disable javaScript: Deselect “Enable JavaScript”
under the “Content” tab. JavaScript is notorious for containing security
vulnerabilities and it is recommended that users only enable it for
trusted sites.
Enable pop-up blocking: Verify that “Block pop-up
windows” is selected under the “Content” tab. This feature should be
turned on by default as it protects users from unwarranted
advertisements and windows.
Don’t sync: Avoid using Firefox Sync. By doing so you prevent Firefox from storing your logins, passwords, and other sensitive information.
Turn on automatic updates: Verify that
“Automatically install updates” is selected in the “Update” tab under
“Advanced.” Doing so will ensure that your browser receives critical
security updates. Verify that “Automatically update Search Engines” is
selected as well.
Use secure protocols: Verify that “Use SSL 3.0” and “Use TLS 1.0” are selected in the “Encryption” tab under “Advanced.”
Tips for Secure Browsing with Microsoft Internet Explorer 10
These settings can be accessed through the “Internet Options” menu.
Configure security settings: Under the “Security” tab, do the following:
Set security zones: IE offers the option to configure
different security settings for different “zones,” including the
Internet, local intranet, trusted sites, and restricted sites. Set up
the zones for Intranet, Trusted Sites, and Restricted sites to your
desired security level.
Set Internet zone security to “Medium High” or higher. This blocks
certain cookie types, enables ActiveX filtering, and implements several
other default settings for increased security.
Disable javaScript: Click “Custom Level,” locate the
“Active Scripting” setting, and select “Disable.” It is recommended that
users disable JavaScript because of the high amount of vulnerabilities
it contains.
Automatically clear history: Select “Delete
browsing history on exit” under the “General” tab. Clearing your history
at the end of each session helps to limit the amount of information IE
saves when you browse.
Configure privacy settings: Under the “Privacy” tab, complete the following steps:
Privacy setting: Set the Internet zone privacy to
“Medium High” or higher. This blocks certain cookie types to prevent
sites from tracking or contacting you without your consent.
Location: Select “Never allow websites to request your physical location.”
Pop-up Blocker: Double check that Pop-up Blocker is enabled.
Configure Advanced Security settings: Scroll down to the “Security” section under the “Advanced” tab and do the following:
Ensure that all default settings are in place. If you aren’t
sure, click “Restore advanced settings” before making any other changes.
Select “Do not save encrypted pages to disk.” This will delete files cached from HTTPS pages when the browser is closed.
Select “Empty Temporary Internet Files folder when browser is
closed.” This prevents IE from storing your personal info (logins,
passwords, activity, etc) beyond your browsing session.
Turn off autoComplete: The AutoComplete feature should be
turned off for forms and usernames/passwords. Keeping AutoComplete
turned off ensures that your sensitive information isn’t being stored
unnecessarily.
Tracking protection: IE’s Tracking Protection
feature keeps your browsing private from specified third-party websites.
This feature can be accessed through IE’s “Safety” menu. In order to
use Tracking Protection you will need to provide a Tracking Protection
List that names all of the sites you don’t want your information being
sent to. You can create a list yourself or download lists online.



















 These settings can be accessed through Chrome’s “Advanced Settings” menu or by navigating to “chrome://settings/."
These settings can be accessed through Chrome’s “Advanced Settings” menu or by navigating to “chrome://settings/." These settings can be accessed through the “Options” menu.
These settings can be accessed through the “Options” menu. These settings can be accessed through the “Internet Options” menu.
These settings can be accessed through the “Internet Options” menu.{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}