Fibre Channel Redundancy
Servers' access to their storage will invariably be mission critical for the enterprise, so we're not going to want to have any single points of failure. Redundant Fibre Channel networks should be put in place, known as Fabric A and Fabric B, or SAN A and SAN B. Each server and storage system host should be connected to both fabrics with redundant HBA ports.
Fibre Channel switches distribute shared information to each other, such as domain IDs, the FCNS database, and zoning. When we configure zoning in a fabric, we only need to do it on one switch, and it will then be automatically distributed to the other switches from there. This makes things more convenient for us, but there's also a potential downside here as well, because if we make a misconfiguration it's going to be replicated between all the switches in the fabric. If an error in Fabric A was able to propagate to Fabric B, this would bring down both fabrics, and it would drop the server's connection to their storage. This would be disastrous.
For this reason, switches in different sides of the fabric are not cross-connected to each other. Both sides of the fabric are kept physically separate. This is different to how we do things in Ethernet LAN networks where we do usually cross-connect our switches.
In Fibre Channel networks, we have two fabrics, Fabric A and Fabric B. End hosts (including the storage system) are connected to both fabrics, but the switches are not. Switches are dedicated to either Fabric A or Fabric B.
In the example below, Server 1 has two HBA ports for redundancy. The first port is connected to Fabric A and the second port is connected to Fabric B.

Redundant SAN Fabrics
I do the same on my storage system which has also got redundant HBA ports. One is connected to Fabric A and the other is connected to Fabric B.
The two fabrics are kept strictly physically separate from each other which is signified that the big red line up the middle of the diagram. Hosts are connected to both fabrics, but the fabrics are kept physically separate from each other. This means that if I have a misconfiguration in Fabric A, Fabric A could go down, but that misconfiguration cannot be propagated to Fabric B. My server would lose connectivity to its storage over Fabric A, but it can still get there over Fabric B so we don't have a complete outage.
Okay, but wait. We're going to have at least two controllers for redundancy of our storage system, so our network topology is actually going to look more like the diagram below.

Redundancy - 2 Controllers
As before, we’ve got the Fabric A and the Fabric B networks which are kept physically separate from each other. Server 1 and Server 2 are connected to both fabrics. Now up at the top, I've got two separate storage system controllers for redundancy. The controllers, just like the servers, act as end hosts, so my storage controllers are connected to both Fibre Channel fabrics.
On a switch in Fabric A, I configure a zone for Server 1 which includes member fcalias S1-A (the HBA port on Server 1 which is connected to the Fabric A network), member fcalias Controller 1-A (the HBA port on Controller 1 which is connected to the Fabric A network) and member fcalias Controller 2-A (the HBA port on Controller 2 which is connected to the Fabric A network). Both Controller 1 and Controller 2 are connected to my Fabric A network, and my server can reach its storage through either controller.

Server 1 Zoning
Also, on that same Fabric A switch, I'll configure a zone for Server 2 which includes member fcalias S2-A (the HBA port on Server 2 which is connected to the Fabric A network), member fcalias Controller 1-A (the HBA port on Controller 1 which is connected to the Fabric A network) and member fcalias Controller 2-A (the HBA port on Controller 2 which is connected to the Fabric A network). Note that the Server 2 zone contains the same HBA ports on the controllers that Server 1 is also connecting on, it’s just the server which has changed.

Server 2 Zoning
I then tie it all together into a zone set. I’ve named my zone set Zoneset-A and it includes zone members Server1 and Server2. I configure that on one of the two Fabric A switches, and it will propagate it to the other switch, which saves me having to do a duplicate configuration on both.

Fabric A Zoneset
I also need to configure my Fabric B switches. I configure a zone for Server 1 which includes member fcalias S1-B (the HBA port on Server 1 which is connected to the Fabric B network), member fcalias Controller 1-B (the HBA port on Controller 1 which is connected to the Fabric B network) and member fcalias Controller 2-A (the HBA port on Controller 2 which is connected to the Fabric B network).

Server 1 Zoning - Fabric B
I also need a zone for Server 2, so I do a similar configuration there. The Server 2 zone includes member fcalias S2-B (the HBA port on Server 2 which is connected to the Fabric B network), member fcalias Controller 1-B (the HBA port on Controller 1 which is connected to the Fabric B network) and member fcalias Controller 2-A (the HBA port on Controller 2 which is connected to the Fabric B network).

Server 2 Zoning - Fabric B
I then tie it all together in my Fabric B zone set. I create a zoneset named Zoneset-B which includes member zone Server1 and Server2. I configure that on one of the two Fabric B switches, and it will propagate it to the other Fabric B switch. That takes care of my zoning on my switches.

Fabric B Zoneset
Each server has four redundant paths to the storage system. Over Fabric A to Controller 1, over Fabric A to Controller 2, over Fabric B to Controller 1, and over Fabric B to Controller 2.
LUN Masking
As well as configuring zoning on the switches, I also need to configure LUN masking on the storage system.

LUN Masking
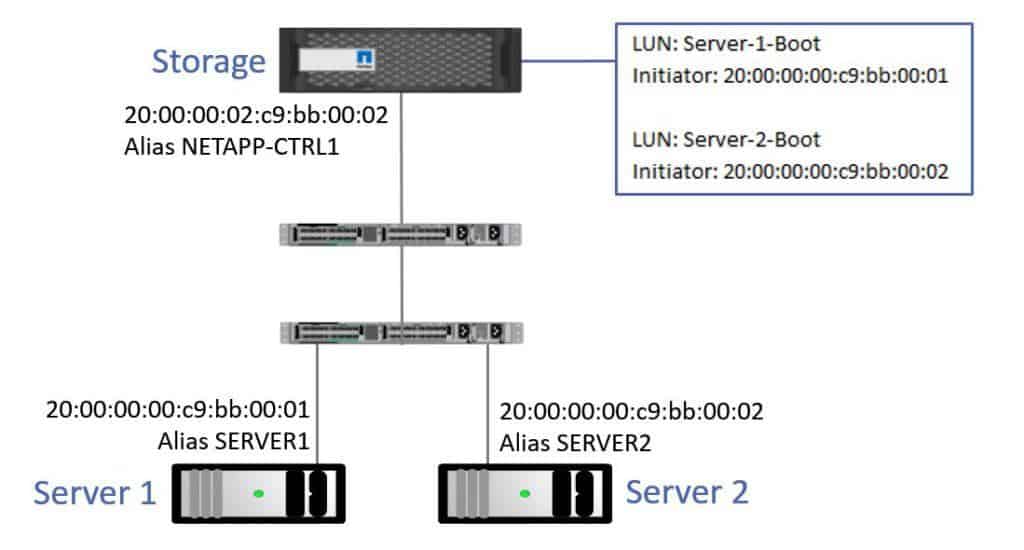
On my storage, I have boot LUNs for Server 1 and for Server 2.
I configure the LUN Masking so that Server 1 can use either of its HBA ports to connect to its LUN. S1-A is an alias for its WWPN which connects to Fabric A, and S1-B is an alias for its WWPN which connects to Fabric A. Both of these aliases are added to the LUN Masking group which is allowed access to the Server 1 LUN. Server 1 is allowed to connect over both Fabric A and Fabric B.
For the Server 2 boot LUN, I do the same thing. I configure the members of its LUN Masking group to be the WWPN aliases Server 2-A and Server 2-B.
Target Portal Groups
The next topic to discuss is TPGs, Target Portal Groups. All of the ports on the storage system which initiators can access their storage through are members of a Target Portal Group. TPGs can be used to control which ports initiators can access the storage target on. If you needed to, you could configure separate TPGs to dedicate a set of ports on your storage system to only your mission critical servers. On most storage systems, all ports will be added to a single TPG by default through which all initiators can access their storage.
In the example below, ports Controller 1-A, Controller 1-B, Controller 2-A, and Controller 2-B are added to a Target Portal Group. Each of those ports will have its own unique WWPN which is in the TPG, and the hosts will learn that they can connect to their storage through any of them.

Target Portal Groups
Asymmetric Logical Unit Assignment
ALUA is used by the storage system to tell the client which are the preferred paths for it to use. Direct paths to the storage system node which owns the LUN are marked as optimized paths. Other paths are marked as non-optimized paths.
Let's look at how this is going to work. We've got the same example we were looking at earlier, where I've got a storage system which is made up of two nodes, Controller 1 and Controller 2. Controller 1 owns the disks where the LUN for Server 1 is currently located.

ALUA
Server 1 can get to its LUN through either Controller 1 or Controller 2, but it would be better for it to go to Controller 1 because that is a direct path. The storage system can give the server all of this information, let it know all of the paths that it can take to get there, and which are the preferred paths. It uses ALUA to do that.
Server 1 learns about Optimized Path 1, which is going through Fabric A and terminates on HBA Controller 1-A.

ALUA Optimized Path 1
It also learns about Optimized Path 2, which is going through Fabric B and which terminates on HBA Controller 1-B.

ALUA Optimized Path 2
Path 1 and Path 2 are optimized paths because they go to Controller 1, which is where the LUN is.
The server will also learn about Non-Optimized Path 3, which goes through Fabric A and terminates on the HBA Controller 2-A.

ALUA Non-Optimized Path 3
And Non-Optimized Path 4, which goes through Fabric B and which terminates on Controller 2-B.

ALUA Non-Optimized Path 4
The server has four different paths that it can take to get to its storage, and two of them are better optimized paths.
During the login process, initiators will detect ports available to connect to their storage on in the Target Portal Group, and ALUA will notify which are the preferred paths.
Multipathing
Multipathing software on the initiator will choose the path or paths to take to the storage. All popular operating systems (all flavors of Windows, Unix, Linux, VMware etc.) have multipathing software which supports active/active or active/standby paths. The client will automatically fail over to an alternate path if the one it is using fails.
Considering our example where we had the two optimized paths and the two non-optimized paths, using our multipathing software on the client we could choose to do active/active load balancing over both optimized paths, or we could do active/standby, where we send the traffic over one of the optimized paths, and if it goes down we fail over to the other optimized path.
Popular manufacturers for HBAs are Emulex and Qlogic, and they both have their own multipathing software which is installed and configured on the client.
Summary
As you've seen, client connectivity to SAN storage is fundamentally different to how Ethernet networking works. I already had a lot of experience in Ethernet networking before I learned storage, and I found this pretty amazing. In Ethernet, if you want to connect a client to a server, you have to point the client at the server's IP address. With Fibre Channel, because of the login process, the client will automagically detect its LUNs.
In Ethernet networking, all the routing and switching decisions are handled by network infrastructure devices. In SAN storage, multipathing intelligence is enabled on the client end host.